The 0 Euros Crawler
Writing a crawler can be enough of a hard problem. But when comes the time to deploy it, you might be looking for the cheapest options out there.
I will not be covering the writing of the crawler. There is way enough content on the web for that. I will be using this simple crawler that outputs the top 10 stories on Hacker News.
Let’s check it works as advertised:
-
make sure you have node and npm installed.
node -v && npm -vIf not, get them from here.
-
clone our sample project and run the
1. basics/get_list_of_links.jsscriptgit clone git@github.com:checkly/puppeteer-examples.git npm install node "1. basics/get_list_of_links.js"The script should return an array that looks a little looking pretty much like this:
[ "Facebook Referred to Kids as Young as Five as “Whales” for Its Monetized Games", "Germany, France, Britain to Launch Mechanism for Trade with Iran", "A proposed API for full-memory encryption", "A “gold standard” study finds deleting Facebook is great for your mental health", "A.I. Could Worsen Health Disparities", "A Coder Who Became a Crime Boss", "Simulating blobs of fluid", "U.S. Changes Visa Process for High-Skilled Workers", "A KGB agent shipped a Sidewinder missile by mail to Moscow (2017)", "Cal Newport on Why We'll Look Back at Our Smartphones Like Cigarettes" ]
Good. Now let’s host this on Gitlab. The nice thing about Gitlab is that it has CI baked in. This will come in handy later as we’ll be trying to run our crawler preiodically
Sign in, create a project, and just follow their instructions.
-
create a project called
my-crawler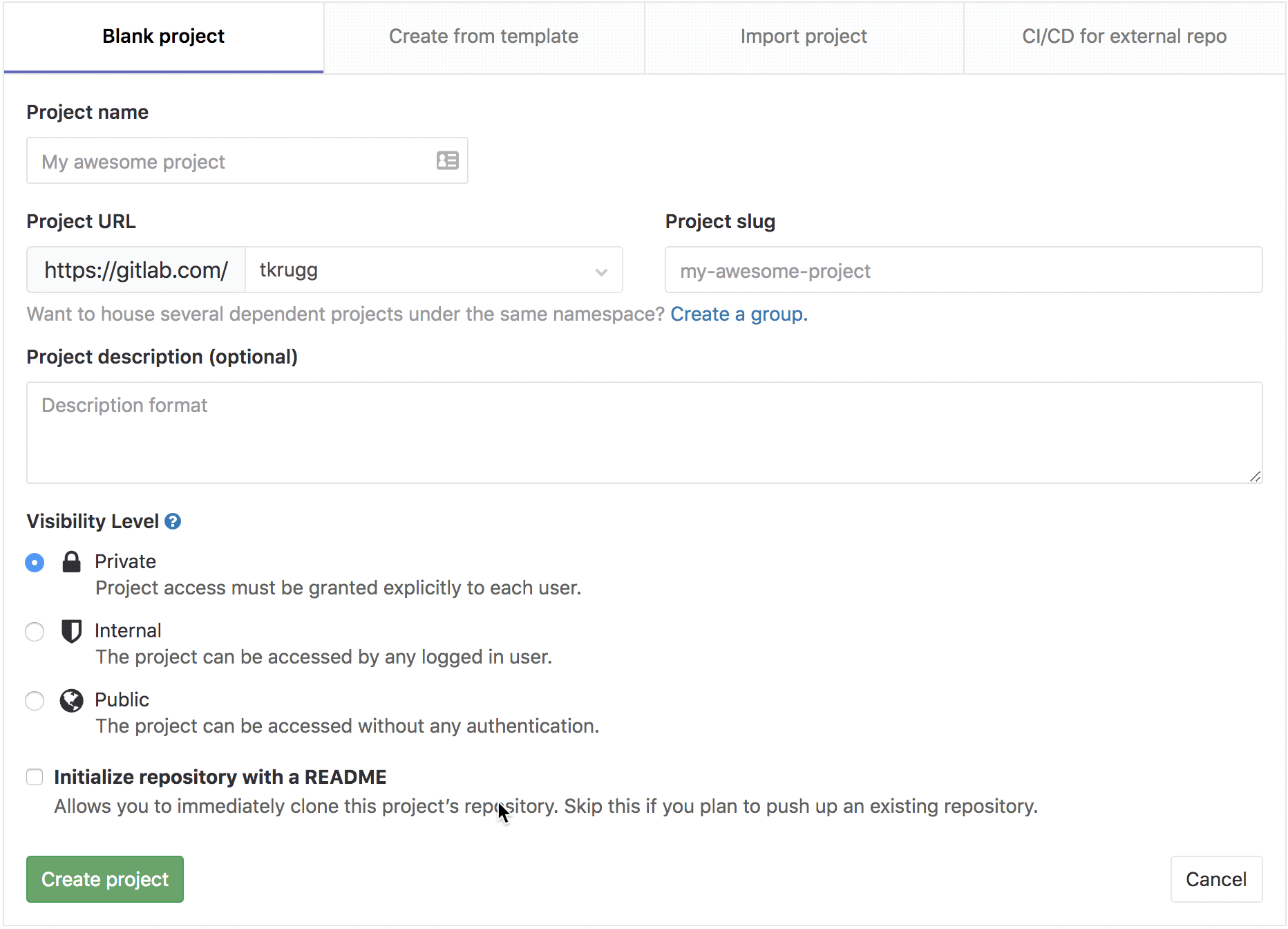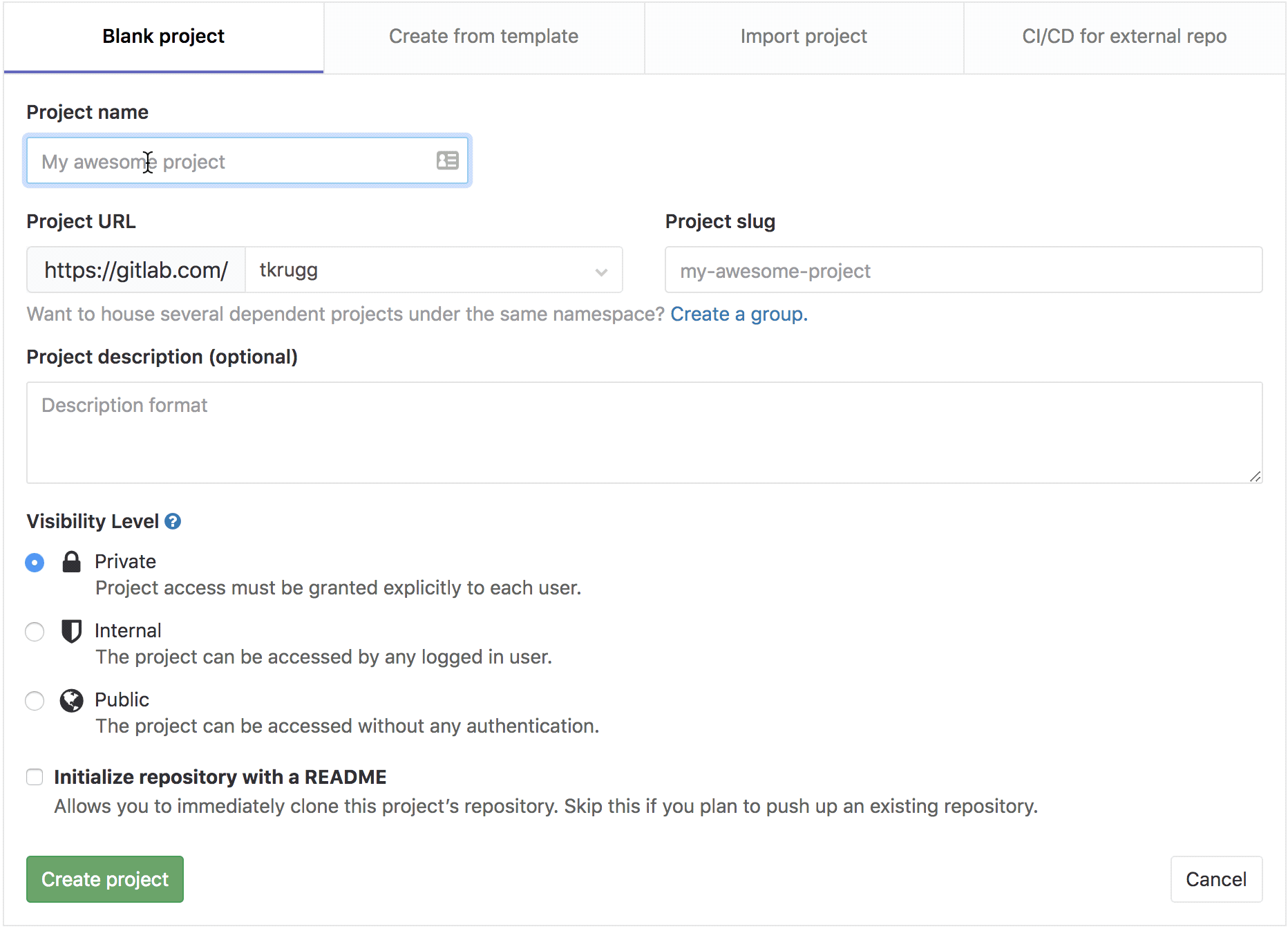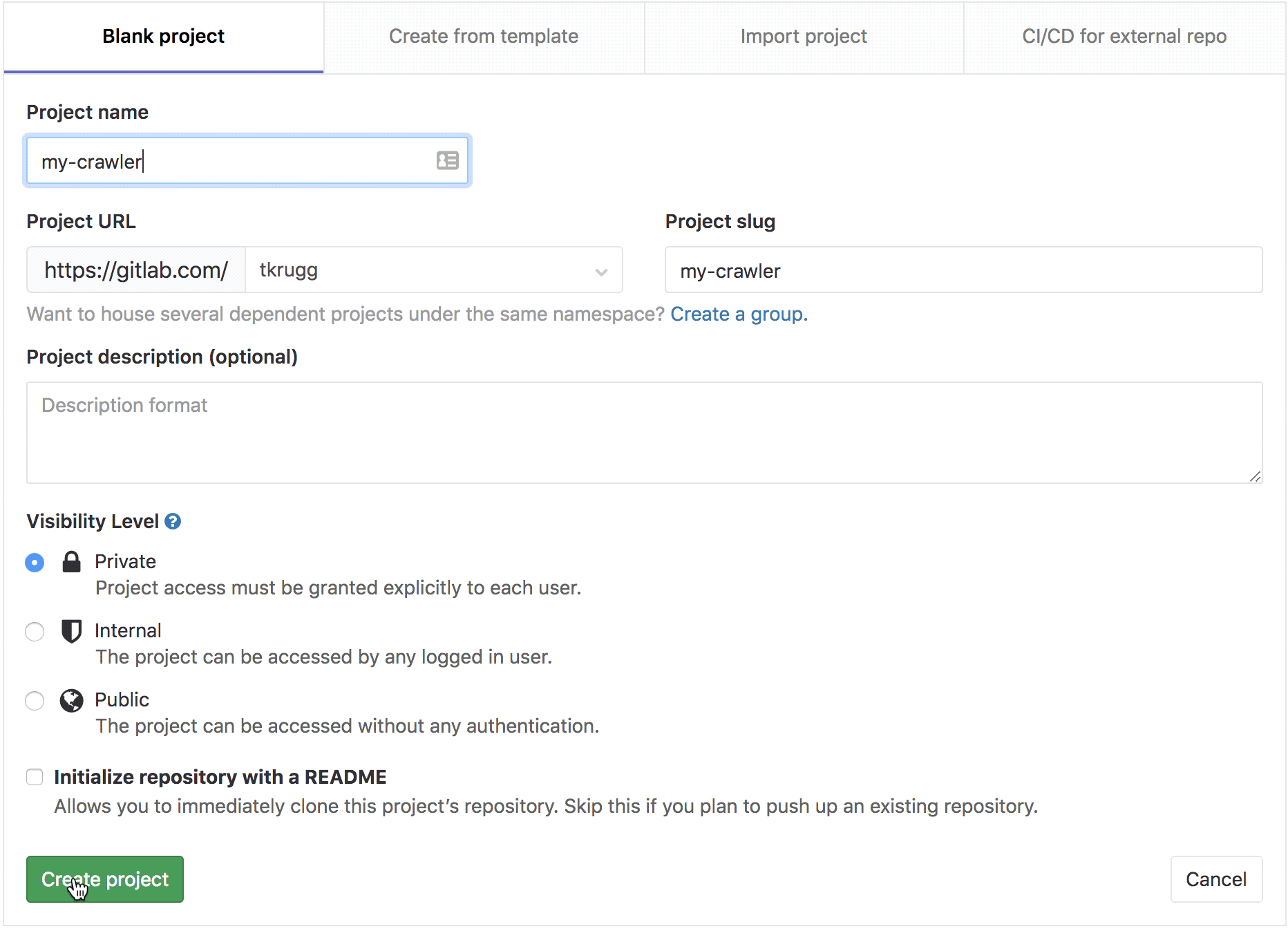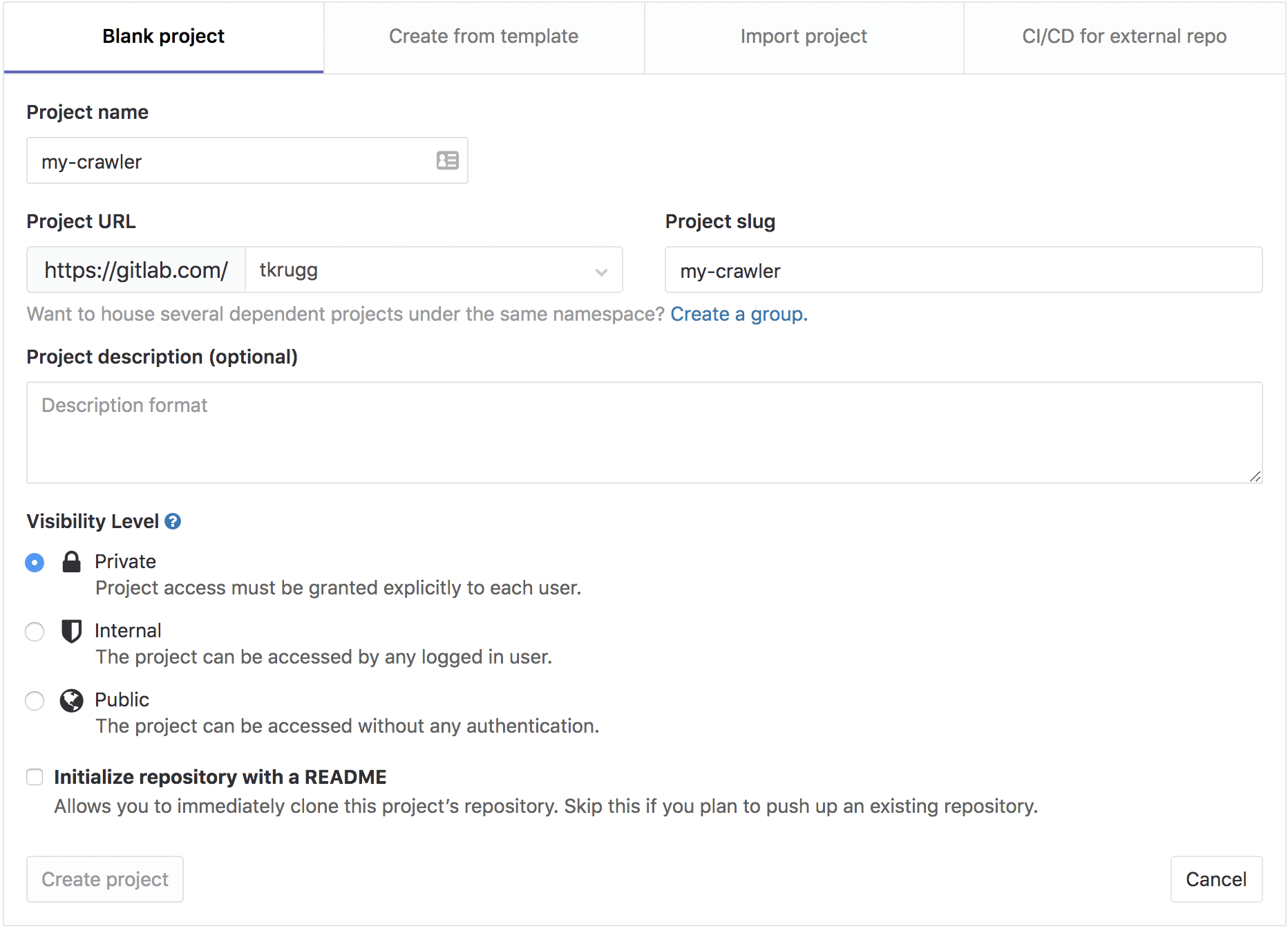
-
follow their instructions for setting up an existing git repository
Problem 1:
Running your crawler periodically
-
In the root directory of the project, create a
.gitlab-ci.ymlwith the following content# .gitlab-ci.yml image: alekzonder/puppeteer stages: - build - run cache: paths: - node_modules/ install_dependencies: stage: build script: - npm install run: stage: run before_script: - npm install script: - node "1. basics/get_list_of_links.js" -
Commit the file to the repo and push
git commit -am "add CI config" && git pushNow the CI pipeline defined inside
.gitlab-ci.ymlwill start. -
Head over to the CI/CD → Pipelines tab of your project to watch it happening.
Now how to run this periodically?
The idea is to leverage the Gitlab’s CI job scheduler to periodically run our crawler. Head over to CI/CD → Schedules, click the New Schedule button, fill in the form and save. Now our crawling script is going to run periodically and for free.
Problem 2:
Persisting the data
To accomplish this we need some kind of database. Most hosted database services are expensive.
Algolia is not a database, but it’s perfect for hosting crawled data. They have a generous Community Plan where you can host up to 10K records, for free, forever.
If you haven’t yet, go on algolia.com and create a free account. By default you get the 14 days trial plan but you can switch to their Community plan.
-
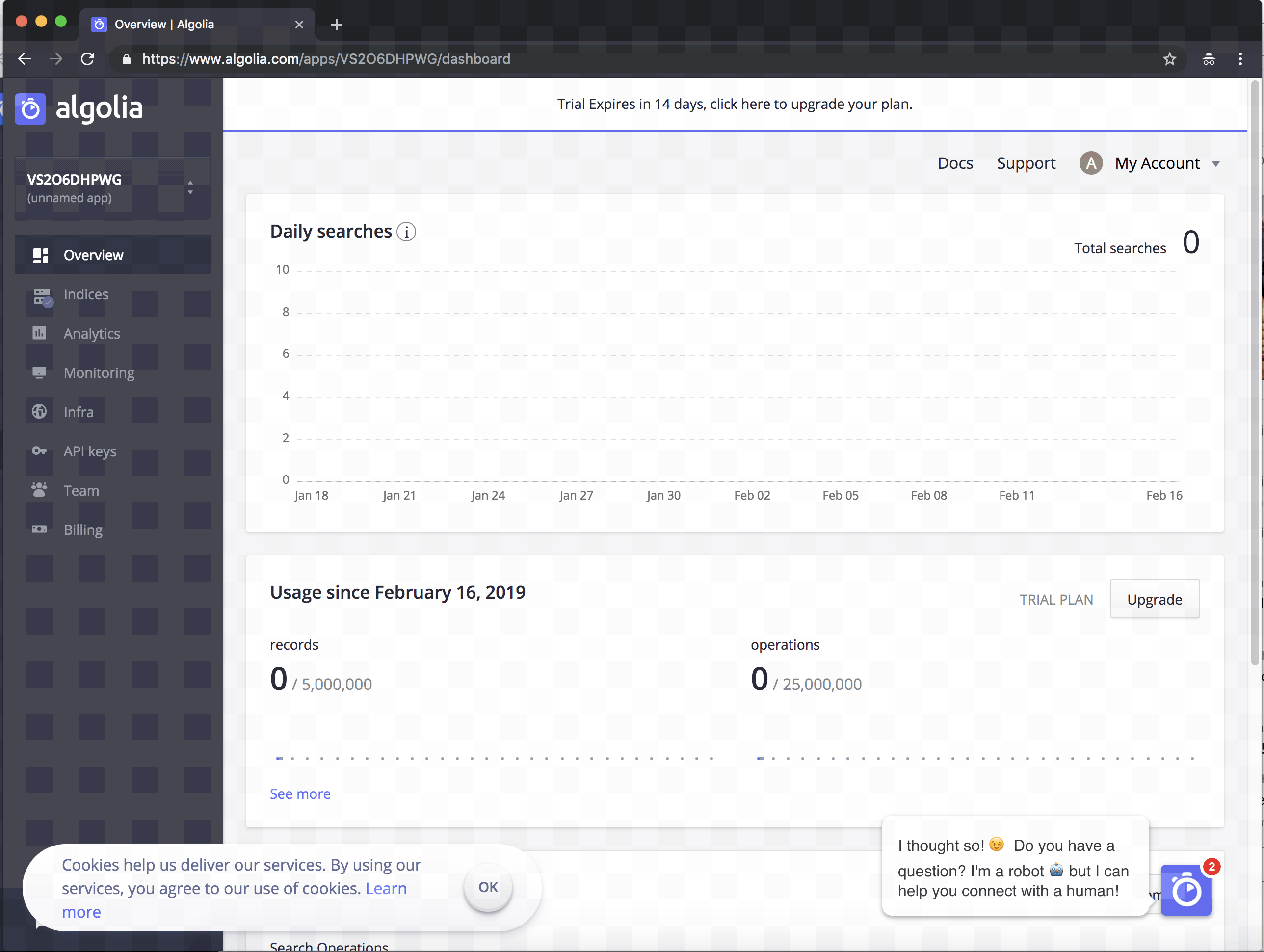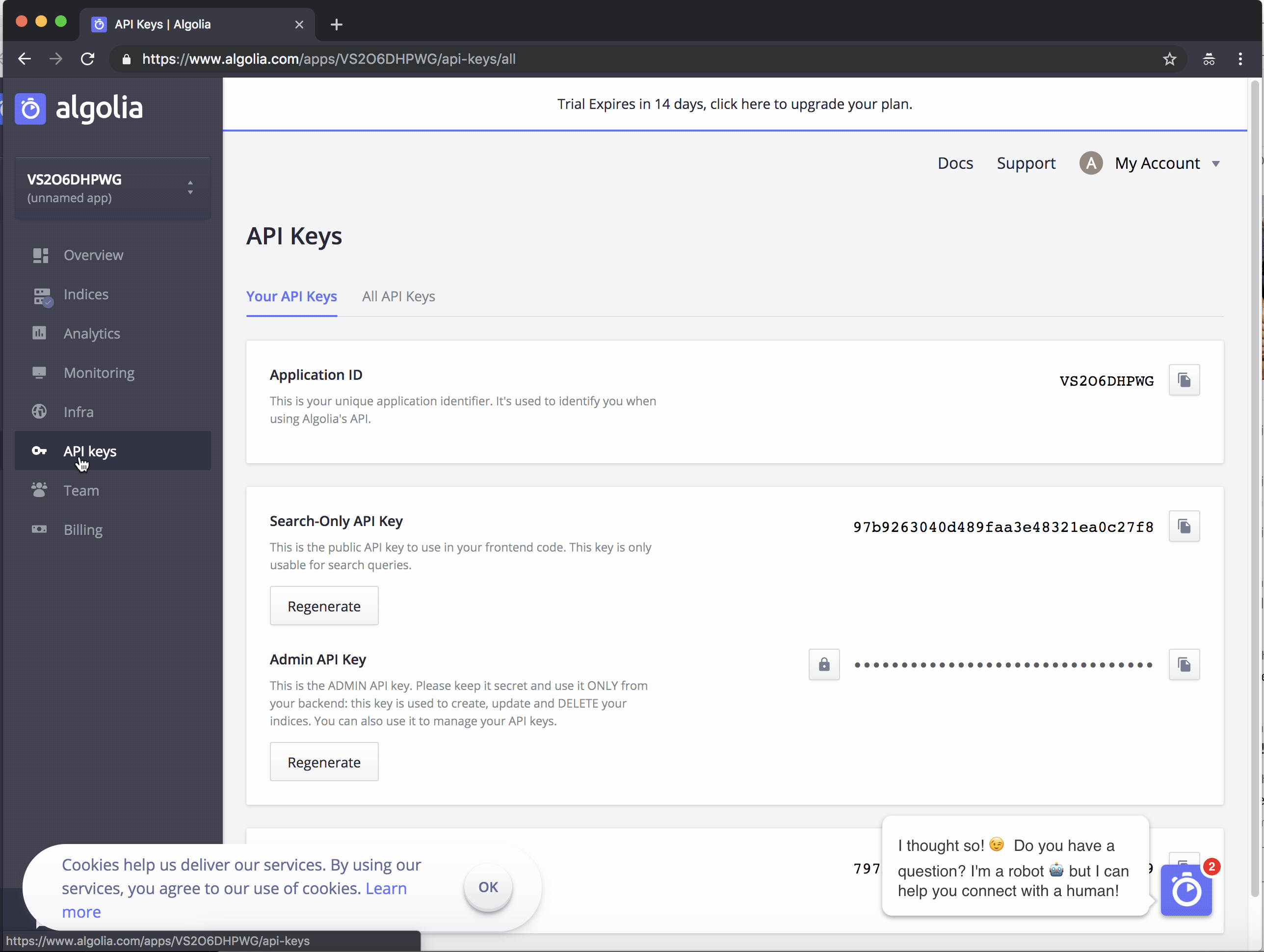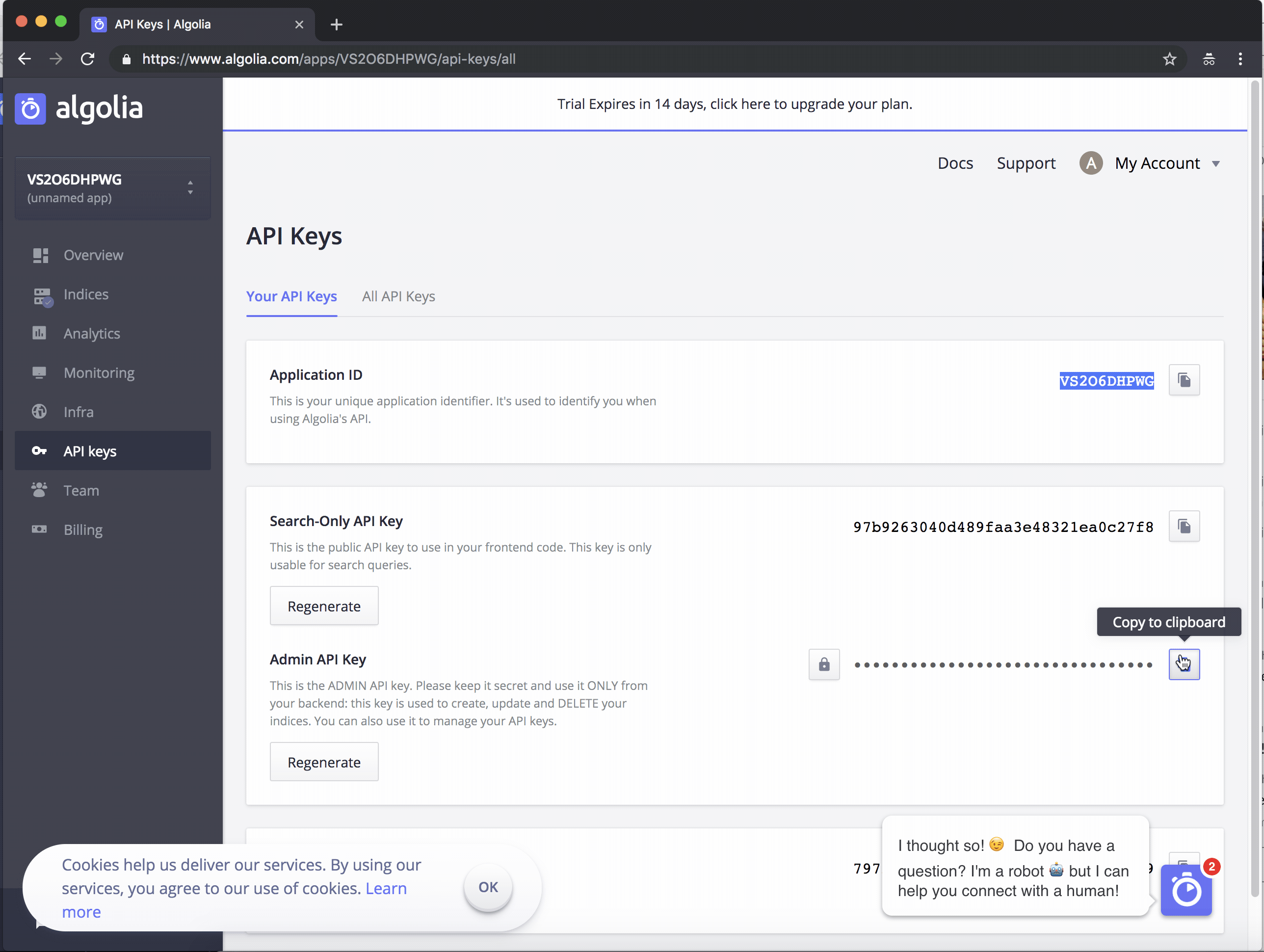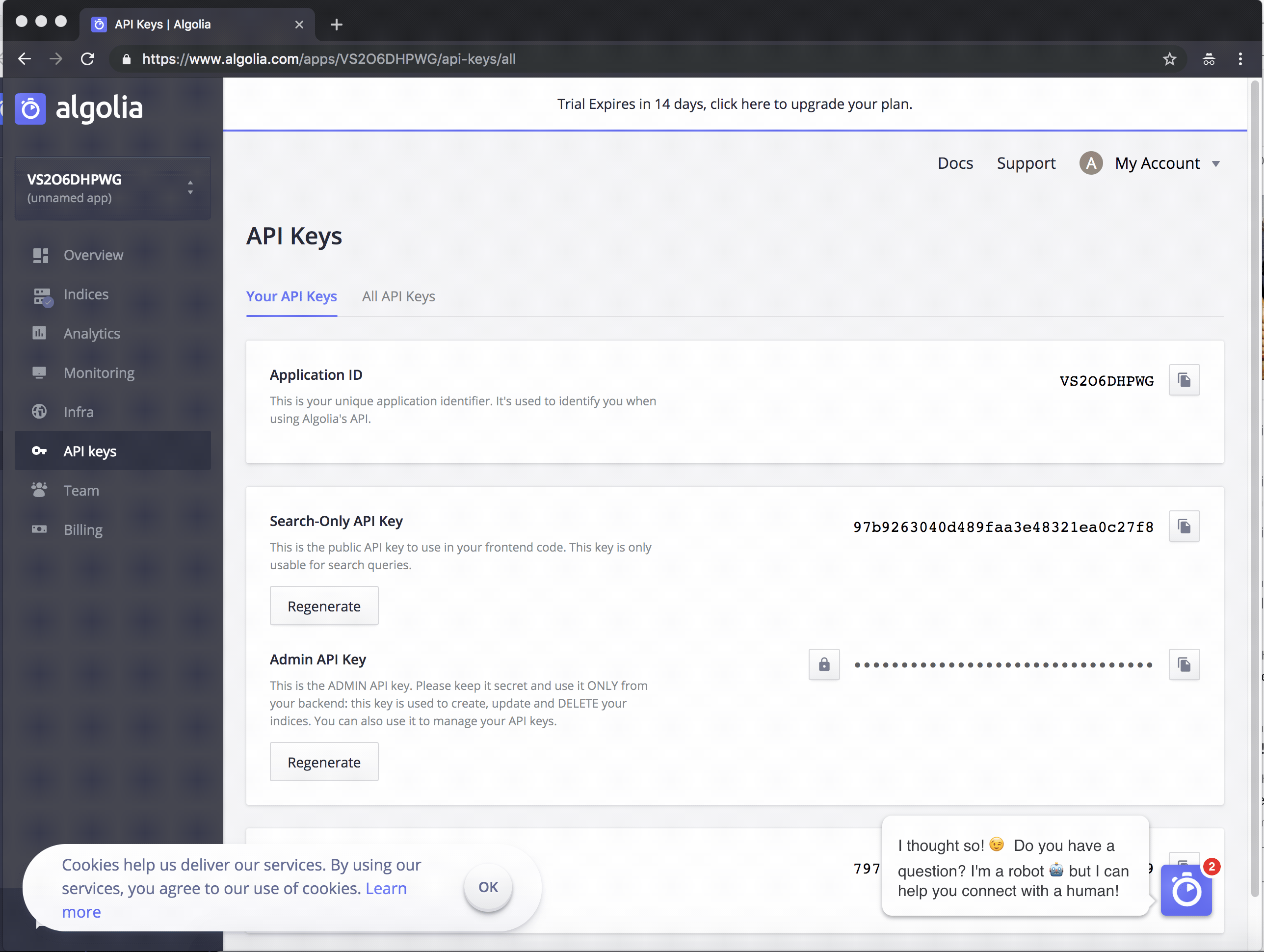
Go to your Algolia Dashboard to get your Application ID and your Admin API Key.
-
Add the Algolia client to our repo
npm install --save algoliasearch-
Modify our script so that it sends the records to Algolia
/** * @name get list of links * * @desc Scrapes Hacker News for links on the home page and returns the top 10 */ const puppeteer = require('puppeteer') const algoliasearch = require('algoliasearch')const client = algoliasearch('applicationId', 'adminApiKey')const index = client.initIndex('stories') ;(async () => { const browser = await puppeteer.launch() const page = await browser.newPage() await page.tracing.start({ path: 'trace.json', categories: ['devtools.timeline'], }) await page.goto('https://news.ycombinator.com/news') // execute standard javascript in the context of the page. const stories = await page.$$eval('a.storylink', anchors => { return anchors.map(anchor => anchor.textContent).slice(0, 10) }) for (const story of stories) { await index.addObject({ objectID: story, // this prevents duplicates title: story, }) } await page.tracing.stop() await browser.close() })() -
Run your script then go back on your Algolia Dashboard to check that your index has been created and your data added.
Problem 3:
Monitoring the status
How to get notified when something goes wrong? When the data you’re crawling has changed in a way that it breaks you crawler.
It is very easily to configure Gitlab to get notified everytime a pipeline succeeds or fails. But another way to set a more immediate notification system it to setup a personal slack then create a channel Incoming webhook you can curl from your CI.
If you choose to go that route, follow learn about how to create an Incoming webhook. You should end up with a URL you can simply curl to send a message to a slack channel.
curl -XPOST https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX -H "Content-type: application/json" -d '{"text": "Crawler just finished running"}'If that works, let’s add it to your CI pipeline
# .gitlab-ci.yml
image: alekzonder/puppeteer
stages:
- build
- run
cache:
paths:
- node_modules/
install_dependencies:
stage: build
script:
- npm install
run:
stage: run
before_script:
- npm install
script:
- node "1. basics/get_list_of_links.js"
after_cript: - curl -XPOST https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX -H "Content-type: application/json" -d '{"text": "Crawler just finished running"}'You’re done. Remember you can manually trigger a CI pipeline to test this setup.
If you think this article was helpful, feel free to share it with whom may care.